If you build APIs, you need to document them. After all, for your users to use your API, they need to know how to use it. A common phrase I like to use as someone who writes a lot of docs is "if it's not documented, it does not exist" - your users can only use a feature if they can discover not only that it exists, but how to use it.
So what is API documentation? How should you write it? What should you include? What are the best practices? In this post I'll answer all of these questions and more and give you some best practices for creating API documentation.
What is API Documentation?
API documentation is the collection of materials your users can use to learn how to effectively build apps using your API. It should contain a range of things:
- API Reference documentation for the endpoints, parameters, request and response objects, and expected status codes
- Examples of using the API
- Examples for the request and response objects to help users know what to pass and what to expect back
- Error messages and status codes that can be returned, and what they mean
- Basic usage guides such as how to get started, authentication, and common scenarios
- Tutorials for more complex scenarios
Why is API Documentation Important?
API documentation is how your users know how to use your API. Without it, they will at best struggle to use your API, and at worst have no idea how to do anything. APIs are lacking in discoverability - without any kind of documentation you literally cannot know what endpoints to call. Even with a list of endpoints, you still need to know what to pass to them, and what to expect back.
For even better discoverability, you can use liblab to generate SDKs from your API specs. SDKs are a much better developer experience than using APIs directly, allowing you to discover the functionality and request and response objects through tools such as IDE autocompletion.
Documentation goes beyond discovering what your API does, it also explains details on how to use it effectively. This can include how to correctly authenticate, how to handle errors, and best practices for using the API.
For example, if you call an endpoint to retrieve some data and you get a 404 status code returned. Does that mean the data does not exist, or that you don't have permission to access it? Good documentation will explain this, and give you the information you need to handle it correctly.
How and where to write API Documentation?
The best place to write API documentation is in your API!
API Specs
When you publish your API, you should always also publish an API spec. This is generated documentation that lists your API endpoints and the request and response objects, and uses standards like Swagger or OpenAPI. The big advantage of this is a lot of the time this can be autogenerated! For example if you are using FastAPI (a Python framework for building APIs) to generate your API, you can have the framework create an OpenAPI spec with no extra code to write.
API specs as a default provide a list of endpoints, what is expected for endpoint parameters, and the request and response objects. These are JSON or YAML documents, so out the box not that easy to read - but there are plenty of tools that can convert these into nice hosted documentation (FastAPI for example has this built in), and again can be built into your API tools or hosting process.
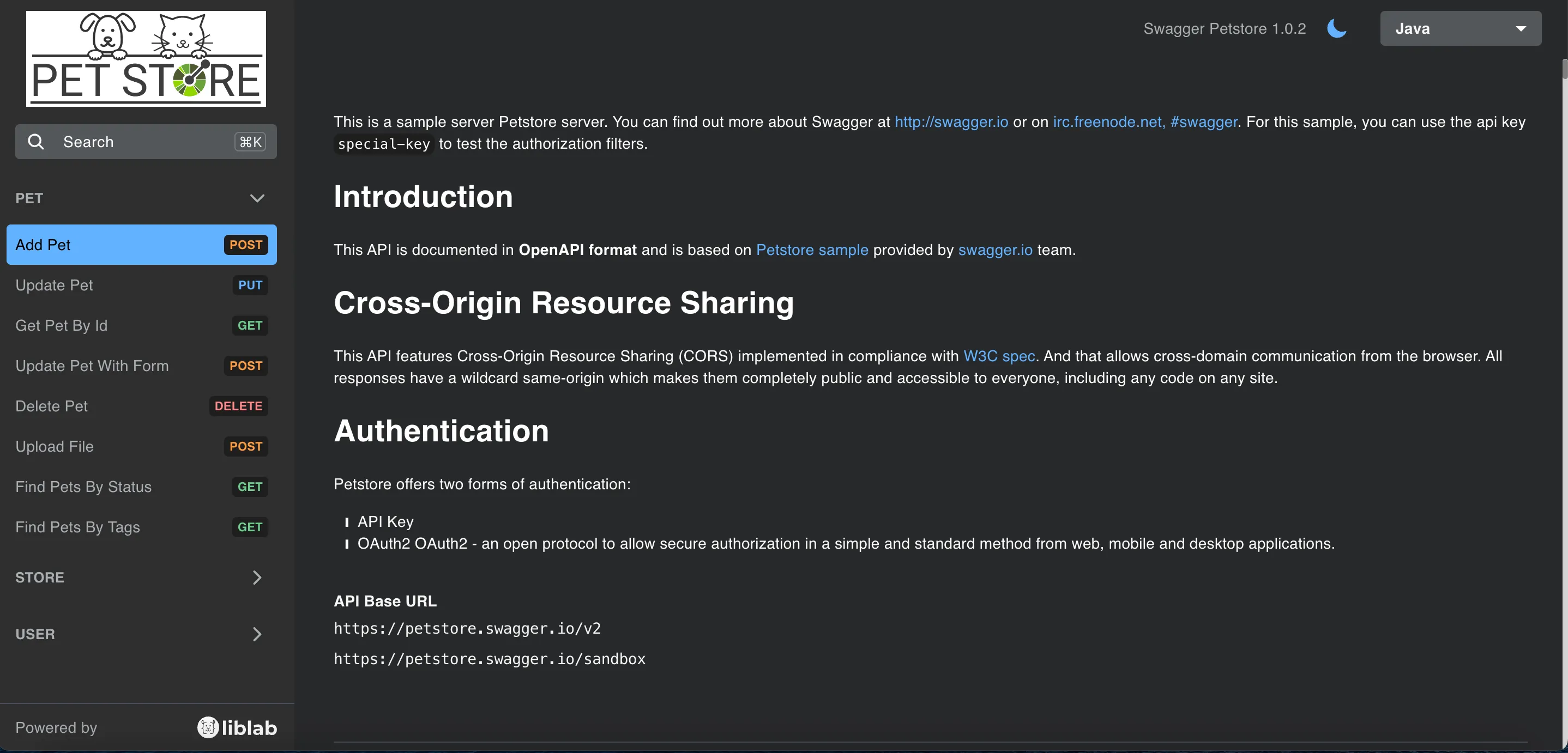
For example, we have a llama store as a reference API for building SDKs against, and it has a spec that is 1115 lines of JSON (you can read it on our GitHub if you want some light bedtime reading). This is small compared to some specs we see at liblab, with over 40,000 lines not uncommon! Reading this much JSON is hard, so there are plenty of tools that render this direct from the API. For example, FastAPI as mentioned before generates OpenAPI specs, as well as hosting generated documentation:
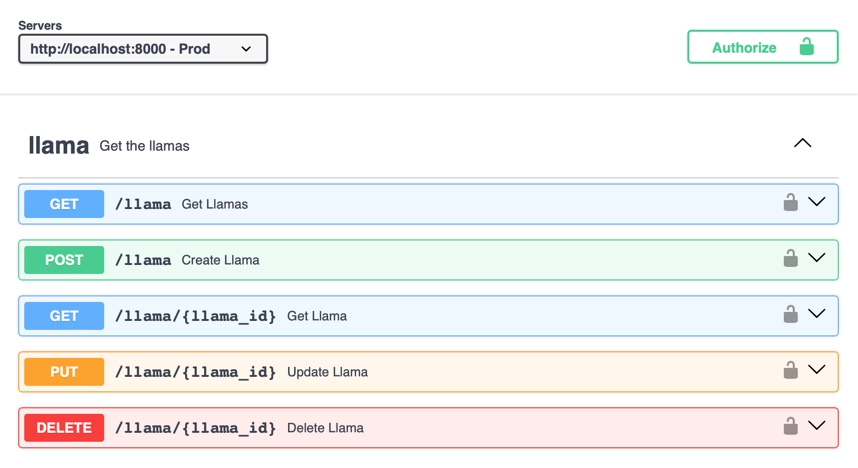
You can see these docs yourself, just clone the llama store, run it locally and access localhost:8000/docs.
Adding documentation to API Specs
As well as these specs listing your endpoints, they can also include a wide range of documentation. This includes:
- Top level API documentation where you can describe in detail the API, such as how to use it, how to authenticate, and best practices
- Endpoints descriptions
- Descriptions and examples for endpoint parameters
- Description and examples for request and response objects
- Descriptions for different status codes, including why they might be returned, and what data might some with them
For example, the llama store has a top level description in the OpenAPI spec:
{
"openapi": "3.1.0",
"info": {
"title": "Llama Store API",
"description": "The llama store API! Get details on all your favorite llamas.\n\n## To use this API\n\n- You will need to register a user, once done you can request an API token.\n- You can then use your API token to get details about the llamas.\n\n## User registration\n\nTo register a user, send a POST request to `/user` with the following body:\n \n```json\n{\n \"email\": \"<your email>\",\n \"password\": \"<your password>\"\n}\n```\nThis API has a maximum of 1000 current users. Once this is exceeded, older users will be deleted. If your user is deleted, you will need to register again.\n## Get an API token\n\nTo get an API token, send a POST request to `/token` with the following body:\n \n```json\n{\n \"email\": \"<your email>\",\n \"password\": \"<your password>\"\n}\n```\n\nThis will return a token that you can use to authenticate with the API:\n\n```json\n{\n \"access_token\": \"<your new token>\",\n \"token_type\": \"bearer\"\n}\n```\n\n## Use the API token\n\nTo use the API token, add it to the `Authorization` header of your request:\n\n```\nAuthorization: Bearer <your token>\n```\n\n\n",
}
}
This is actually set in code - something that FastAPI supports is adding these kinds of OpenAPI values to your API code:
app = FastAPI(
servers=[{"url": "http://localhost:8000", "description": "Prod"}],
contact={"name": "liblab", "url": "https://liblab.com"},
description="The llama store API! Get details on all your favorite llamas.\n\n## To use this API\n\n- You will need to register a user, once done you can request an API token.\n- You can then use your API token to get details about the llamas.\n\n## User registration\n\nTo register a user, send a POST request to `/user` with the following body:\n \n```json\n{\n \"email\": \"<your email>\",\n \"password\": \"<your password>\"\n}\n```\nThis API has a maximum of 1000 current users. Once this is exceeded, older users will be deleted. If your user is deleted, you will need to register again.\n## Get an API token\n\nTo get an API token, send a POST request to `/token` with the following body:\n \n```json\n{\n \"email\": \"<your email>\",\n \"password\": \"<your password>\"\n}\n```\n\nThis will return a token that you can use to authenticate with the API:\n\n```json\n{\n \"access_token\": \"<your new token>\",\n \"token_type\": \"bearer\"\n}\n```\n\n## Use the API token\n\nTo use the API token, add it to the `Authorization` header of your request:\n\n```\nAuthorization: Bearer <your token>\n```\n\n\n",
openapi_tags=tags_metadata,
version="0.0.1",
redirect_slashes=True,
title="Llama Store API",
)
This then gives these docs:
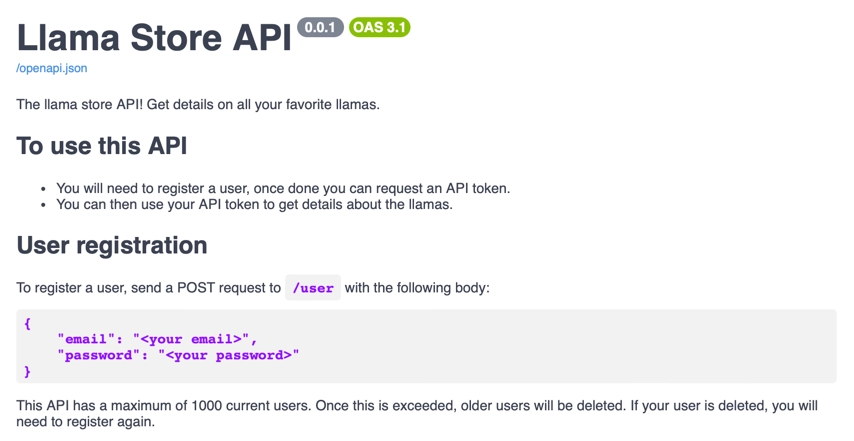
You may notice that the description has markdown! This is nicely rendered in the docs. This is a great way to add rich documentation to your API specs, and is a great way to add tutorials and best practices. This rich documentation can also provide code examples, error messages and more.
This generated documentation should not just be made available via your API, but also hosted on a public documentation site.
Additional documentation
As well as documenting your API in the API spec, you can also add additional documentation on your public documentation site. Your API docs become the reference documentation, but you should add tutorials, how to guides, and best practice documentation as well.
Your API spec documentation can define what each endpoint does and how to call it, but it may not define the correct flow that a user might take for a typical task. For example, if your API has long running tasks, you may need to document how a user can trigger a task, check the status, then retrieve the result, all using different endpoints.
Who Should Write API Documentation?
As someone who started out in engineering before I moved to developer relations, I know how hard it is to write documentation. It's not something that comes naturally to most engineers, and it's not something that most engineers enjoy doing. But it is something that is important, and something that needs to be done.
In a perfect world, your documentation would be written by a dedicated technical writer, working in collaboration with the engineers to understand how the API works, and with the product teams to understand the end-to-end user experience. They should then feed this documentation back to the engineers to add to the API spec.
We all don't live in a perfect world though, so the next best thing is to have the engineers and product teams write the documentation. They know the API best, and can write the most accurate documentation.
Ideally you should use a framework for your API that makes writing these docs easy - for example FastAPI as mentioned before makes it easy to add documentation to your API code, and then generates the OpenAPI spec for you. This way you can even 'enforce' this by having a check for documentation in your pull request review process, or in a linting check in your CI/CD pipeline.
As an API provider - make sure you have documentation firmly in your process!
API Documentation Best Practices
Here are some API documentation best practices for writing api docs:
1 - Write in clear language
A good rule for everyone writing any documentation, including creating API documentation, is to be as clear as possible. Avoid jargon, unless it is necessary technical terminology for your product, and find ways to define this, or link to other documentation. There are some things you can assume your users know, but don't assume they know everything. It's helpful to define a minimally qualified reader, which defines the minimum knowledge or skills for each piece of documentation, and write for them.
For example, you can assume that your users know how to call an API (though a link to a guide on this is always helpful), but you can't assume they know how to authenticate, or what a JSON object is. As you document more advanced functionality, you can assume some knowledge of your API, such as assuming they know how to create a new user when documenting how to interact with that user.
2 - Show, don't tell
For any documentation, showing is better than telling. Examples always help - it's amazing how much easier it is to understand something when you can see it in action.
This is true for API documentation as well. If you want to teach someone how to get data from your API, show them the request, and what response they will get. When using your API, users could be using one of many programming languages, so provide code examples for the main ones. For example, if your API is targeted towards an enterprise, have code examples in C# and Java.
3 - Add references docs, tutorials, and guides
Documentation comes in a variety of modes, and it is good to implement them all. These are:
- Tutorials - learning oriented
- How to guides - task oriented
- Explanation - understanding oriented
- Reference docs - information oriented
I won't go into these in more depth here, but read up on Diátaxis for more information.
Reference docs and explanation should be in your API specs, and hosted on your public documentation site. Tutorials and how to guides can be on your public documentation site.
Your tutorials should also always have a quickstart. Humans like instant gratification, so being able to very quickly get started with an API is a great motivator to learn more and use it more. If a user struggles to even do the basics, they are likely to drop your API and move to a competitor. That initial documentation is crucial to keeping users engaged.
4 - Add code samples
Code samples always help! You users are engineers after all, and will be accessing your API using code. Code samples allow them to quickly craft API calls, and see what they will get back. They also allow you to show best practices, such as how to handle errors, and how to handle pagination.
Obviously the best code samples are using an SDK instead of an API - something liblab can help with!
5 - Keep it up to date
This is sometimes the hardest. When an API has no documentation there's often a big effort around writing api documentation once, usually before a big release, but no continuous time given to keeping the api docs up to date - changing them as features change or adding new features.
This is why it's important to have documentation as a part of your engineering and release process. Don't let any feature out the gate without docs, add documentation to your PR processes, or add checking for docs to your CI/CD pipelines. If you have a dedicated technical writer, they can help with this, but if not, make sure the engineers and product teams are writing the docs as they write the code.
Feature flags can be particularly helpful here, allowing features to be released, but not turned on until the docs are ready (and maybe turned on for the doc writers so they can verify what they are writing).
6 - Make it accessible
Accessibility is important for documentation as well as your API. Make sure your documentation is accessible to everyone, including those with visual impairments. This means when you render it on a docs site using good color contrast, and making sure any images have alt text. It also means making sure your documentation is accessible to screen readers, and that any code samples are accessible.
You also may have users who don't speak the default language of your company, so consider translating your documentation into other languages. This is a big effort, but can be done in stages, starting with machine translations for the most popular languages for your users, and moving on to human efforts.
7 - Make it someones problem
The best way to ensure you have good docs, is to have someone responsible. This is the person who can hold up a release or turning on a feature flag if docs are not ready. Without someone taking responsibility, it's easy for docs to be forgotten about, and for them to become out of date. "Oh, we'll do it later, we need to release for customer X" is the start of the slippery slope to no useful docs.
Make your SDKs better with good API documentation
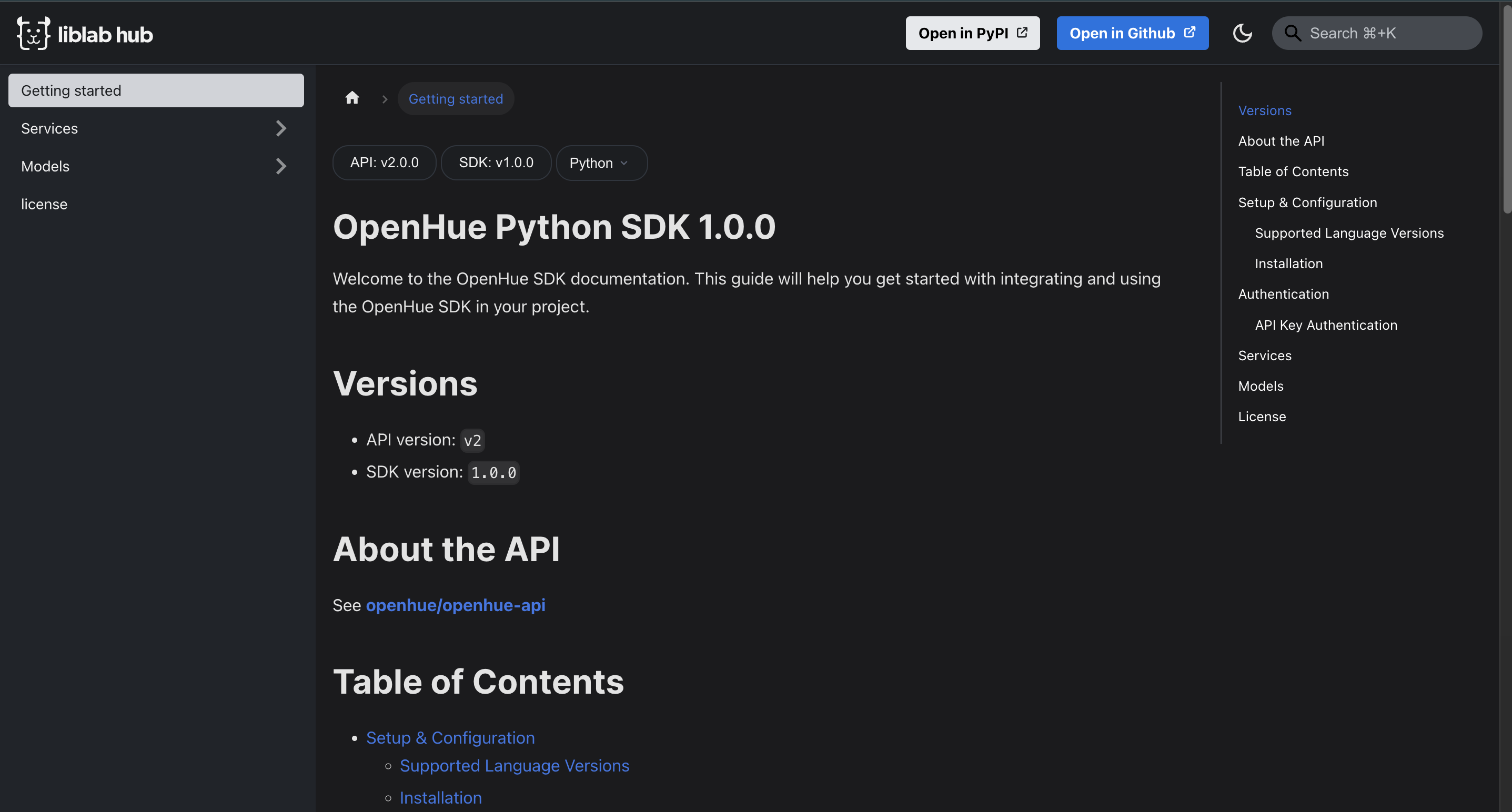
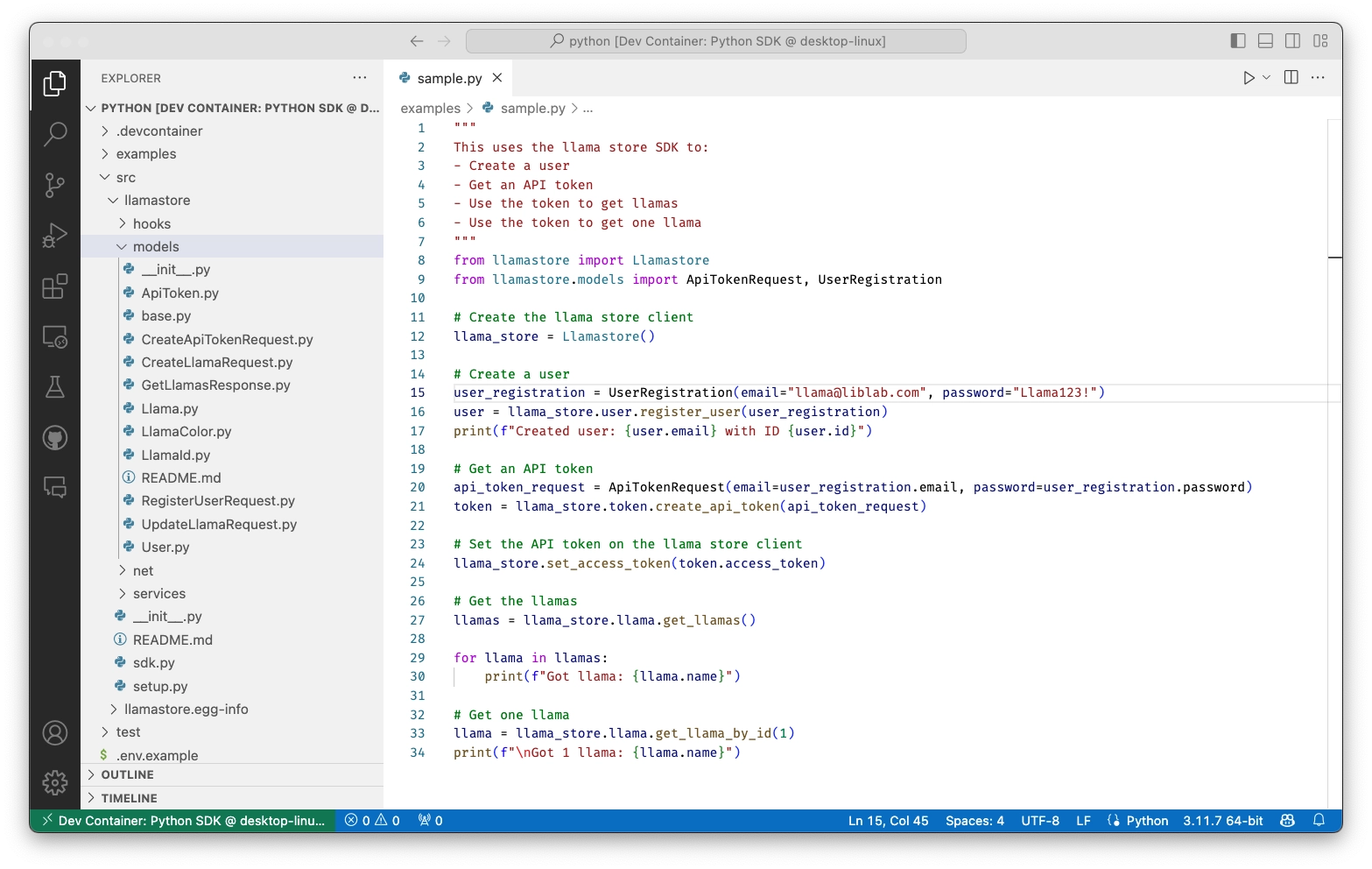
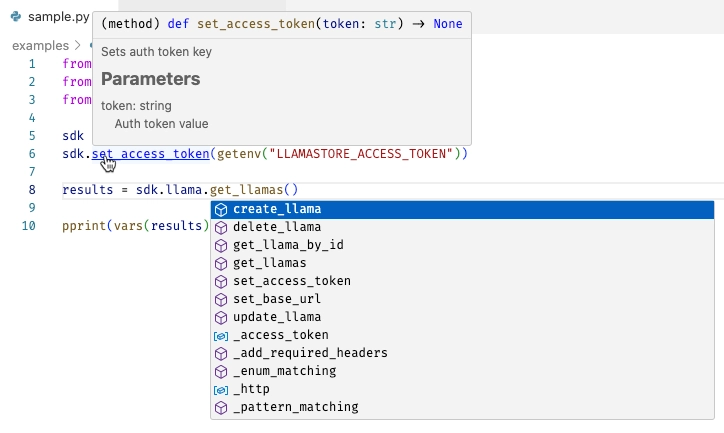
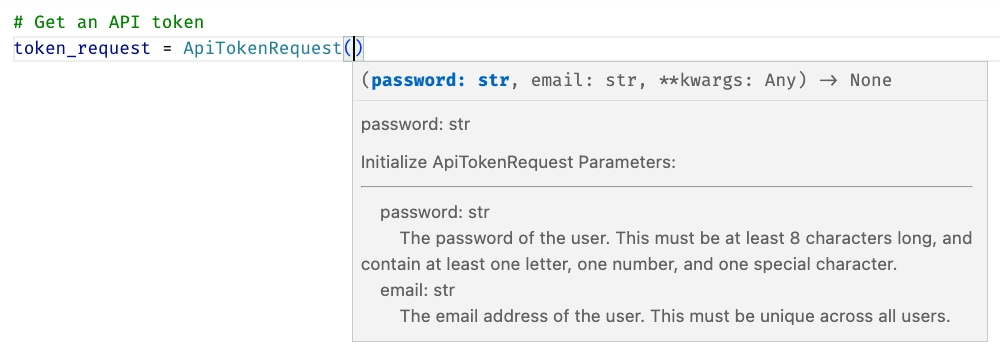
The other big upside of good API documentation is it can automatically become the documentation for your SDK. With liblab, every time you generate an SDK, the documentation and examples are lifted from your API spec and included in the SDK. For example, with the following component in your API spec:
APITokenRequest:
properties:
email:
type: string
title: Email
description: The email address of the user. This must be unique across all users.
password:
type: string
title: Password
description: The password of the user. This must be at least 8 characters long, and contain
at least one letter, one number, and one special character.
You would get the following documentation in your Python SDK:
Conclusion
Your users deserve good documentation for your API, and for any SDKs generated from them. With liblab, you can generate high quality SDKs from your API specs, and include the documentation and examples from your API spec in the SDKs. This means you can focus on writing good API specs and writing good API documentation, and let liblab do the hard work of generating the SDKs and documentation for you.