At liblab we generate software development kits, or SDKs, for your APIs. But what do we mean by 'SDK generation', and how does it work? This post explains everything you need to know about SDK generation, and how it can help you make your APIs more accessible.
What is SDK Generation?
Put simply, SDK generation is the process of automatically generating SDKs from an API specification. You have an API exposed using something like REST, and you want to make it easier for developers to access that REST API.
You could just let them access the API directly, but this relies on your user not only being experts in their own domains, but also knowing how to make REST calls, and to a certain degree the best practices for using your API. By creating an SDK, you are building a layer of abstraction over that API, embedding those best practices into the internals of the SDK code, and providing a nicer interface to your API in the programming languages that the developer is using.
In my experience, every team of developers that accesses APIs will always build some kind of layer of abstraction themselves. This will contain things like wrapper objects for the requests and responses to avoid using JSON, and service classes that wrap the REST requests in methods. These layers of abstraction may also include things like authentication, refreshing access tokens, retries, and error handling. This takes a lot of work, and is often not shared between teams in an enterprise who are all using the same API.
By auto generating an SDK, you can provide this layer of abstraction for your API, and ensure that all developers are using the same best practices. This cuts down on the boilerplate code being written, and allows developers to focus on solving real problems instead of wrapping JSON and REST. You don't write swathes of code, you use a tool that will do all the hard work for you, taking in your API and spitting out an SDK.

This auto generation also handles updates - add a new endpoint to your API? Regenerate the SDK, and the new endpoint will be available to your users. This means that your users will always have access to the latest version of your API, and you don't need to worry about them using an old version of your SDK.
Read more on a comparison between APIs and SDKs.
How Does SDK Generation Work?
SDK generation is computers writing code for you. A tool takes an API specification, and generates code that can be used to access that API. The SDK code is generated in the programming languages of your choice.
REST API Validation
Every generated SDK starts from an API specification. These use standards like OpenAPI to define the API - including the endpoints that can be called, and the expected data that will be sent as the request body, or the response of the call.
For example, your spec might have an endpoint called llama/{llama_id} that takes a llama Id in the URL, and returns a JSON object containing the details of that llama. The spec will define the URL, the HTTP method (GET), and the expected response body.
/llama/{llama_id}:
get:
tags:
- llama
summary: Get Llama
description: Get a llama by ID.
operationId: get_llama_by_id
parameters:
- name: llama_id
in: path
required: true
schema:
type: integer
description: The llama's ID
title: Llama Id
description: The llama's ID
responses:
'200':
description: Llamas
content:
application/json:
schema:
$ref: '#/components/schemas/Llama'
type: array
items:
$ref: '#/components/schemas/Llama'
title: Response 200 Get Llama By Id
The endpoints use schemas to define the objects that are sent or returned. In the example above, the response is defined as an array of Llama objects. The schema for a Llama object might look like this:
Llama:
properties:
name:
type: string
maxLength: 100
title: Name
description: The name of the llama. This must be unique across all llamas.
age:
type: integer
title: Age
description: The age of the llama in years.
color:
allOf:
- $ref: '#/components/schemas/LlamaColor'
description: The color of the llama.
rating:
type: integer
title: Rating
description: The rating of the llama from 1 to 5.
id:
type: integer
title: Id
description: The ID of the llama.
type: object
required:
- name
- age
- color
- rating
- id
title: Llama
description: A llama, with details of its name, age, color, and rating from
1 to 5.
Before the SDK can be generated, the API needs to be validated. For example - the llama/{llama_id} endpoint returns a llama object defined using the #/components/schemas/Llama schema. If this doesn't exist, then the SDK cannot be successfully generated. The validation will also look for other things - for example, does the endpoint have operationId defined for each verb, which is used to generate the method name in the SDK. Are there descriptions for each endpoint, which can be used to generate the documentation for the SDK.
liblab can validate your API spec, and will give you a list of issues to resolve before you generate your SDK. The better your spec, the better your SDK will be.
SDK Generation
Once your API has been validated, the SDK can be generated. This is done by taking the validated API specification, and adding a sprinkle of liblab magic to generate the SDK code. This 'magic' is smart logic to build out model objects that match the requests and responses, as well as generating services that wrap the REST calls. The models handle missing fields in the responses, or patterns that are defined (such as ratings needing to be between 1 ans 5, or an email address field needing to be a valid email). The services implement required logic such as retrying failed requests, handling authentication, refreshing access tokens, and handling errors.
SDK generation also understands the programming language that you want to generate the SDK in. This means that the generated code will be idiomatic for that language. For example naming will be idiomatic to the language, so for the above llama example, the service will be called Llama in Python and C#, but the method to get a llama by Id will be get_llama_by_id in Python, and GetLlamaByIdAsync in C# - using snake case for Python and Pascal case for C#. The generated code will also use the idiomatic way of handling asynchronous calls - for example, in C# the generated code will use Task and async/await to handle asynchronous calls, naming them with the Async suffix.
A lot of the features generated in the SDK can be customized. For example, you can customize how retries are handled, including how many attempts and the time between retries. You can even hook into the API lifecycle and add custom logic to handle requests before they are sent, or responses before they are returned to the caller.
Documentation Generation
As well as generating SDKs, liblab also generates documentation for the SDK from the validated API. This documentation not only shows how to call the API directly using tools like curl, but also code samples showing how to use the SDK. This way developers can literally copy and paste code examples from your documentation to get started quickly using your SDK.
This documentation is built using the descriptions and examples from the API spec, so the better the documentation in the spec, the better the documentation for the SDK. Your code samples will include these examples.
Packaging
Its all very well to create an SDK, but you need to be able to store the code of your SDK somewhere, and distribute it to your users, and this is typically via a package manager like PyPi, NPM or NuGet. liblab generates all the relevant package manifest files, and can raise a pull request against your repository to add the generated SDK code. You can then review the PR, merge it, and publish the package to your package manager of choice, either a public package manager, or an internal one.
Best Practices For SDK Generation
Here are some best practices for SDK generation, to help you get the most out of your generated SDKs.
Understand Your Users’ Needs
The most important part of any software development process is:
Know thy user
Understand what your user needs. This might be their requirements for your SDK, or it will be your knowledge of how the SDK should work to give your users a seamless experience.
Generate for the users preferred programming languages
What programming languages are your users likely to use? For example, if you are developing for a large enterprise, chances are a C# and Java SDK might have a larger audience than a Go SDK. Smaller companies might be more likely to use Python or TypeScript.
Build for your users - and the big advantage of using SDK generation tools like liblab is growing the languages you support can be as simple as adding a new language to your config file, then packaging up the SDK for distribution to your users.
Simplify the Authentication Process
Authentication is hard, and everyone hates writing code to authenticate against an API. Make it easy for your users by handling authentication in the SDK. This might be as simple as providing a method to set the access token, or it might be more complex, such as handling the OAuth flow for your users by hooking into the API lifecycle.
SDKs can also handle refresh tokens, so if you want a persistent connection to your API, you can handle refreshing the access token in the SDK, and your users don't need to worry about it. This is very useful when writing server code that will run for months or even years on end, rather than desktop apps where the user will log in each day.
Have a good API spec
The old adage of 'garbage in, garbage out' applies here. If your API spec is not well defined, then the generated SDK will not be well defined.
Make sure you have tags and operation Ids defined, so the SDK services can be well named and grouped correctly - SDK generation uses the tag property to group endpoints into services, and the operationId to name the methods in the service (adjusting for different programming languages of course). For example, with this spec:
/llama:
get:
tags:
- llama
operationId: get_llamas
/llama_picture:
get:
tags:
- llama_picture
operationId: get_llama_pictures
This will give:
| Service name | Method name (Python) | Method Name (C#) |
|---|---|---|
llama | get_llamas | GetLlamasAsync |
llama_picture | get_llama_pictures | GetLlamaPicturesAsync |
Without these, the endpoints will be grouped into one service, and the names will be generated from the method and the URL, which might not give what you want.
For help on improving your OpenAPI spec, check out our Why Your OpenAPI Spec Sucks blog post.
Have Examples and descriptions
When coding, examples always help, giving developers something to start from when using a new SDK or library (the old joke about most code bring copied and pasted from Stack Overflow). The same applies to SDKs - if you have examples in your API spec, then these will be used to generate examples in the SDK documentation, and your users can copy and paste these examples to get started quickly.
Examples also help your users understand what data they should send to your API, and what they will get back. This is especially important for complex objects.
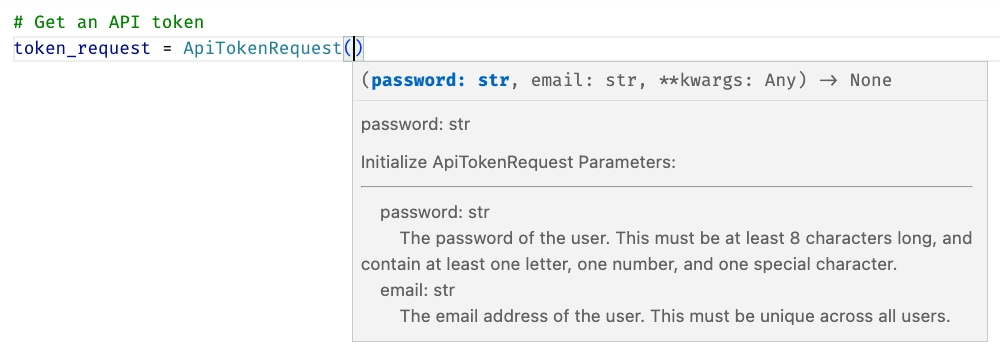
Descriptions are converted into code documentation, both in the SDK and in the docs that accompany it. These make it easier for your users to understand what the SDK is doing, and how to use it. In the example below, the documentation comes from the description in the API spec. The spec is:
APITokenRequest:
properties:
email:
type: string
title: Email
description: The email address of the user. This must be unique across all users.
password:
type: string
title: Password
description: The password of the user. This must be at least 8 characters long, and contain
at least one letter, one number, and one special character.
This gives the following documentation in your Python SDK:
Conclusion
SDKs make APIs more accessible for your users, and automatically generating SDKs makes it easier for you to provide SDKs for your APIs. liblab can help you generate SDKs for your APIs, and we can help you with the process of generating SDKs, and the best practices for doing so. Get in touch to find out more.
