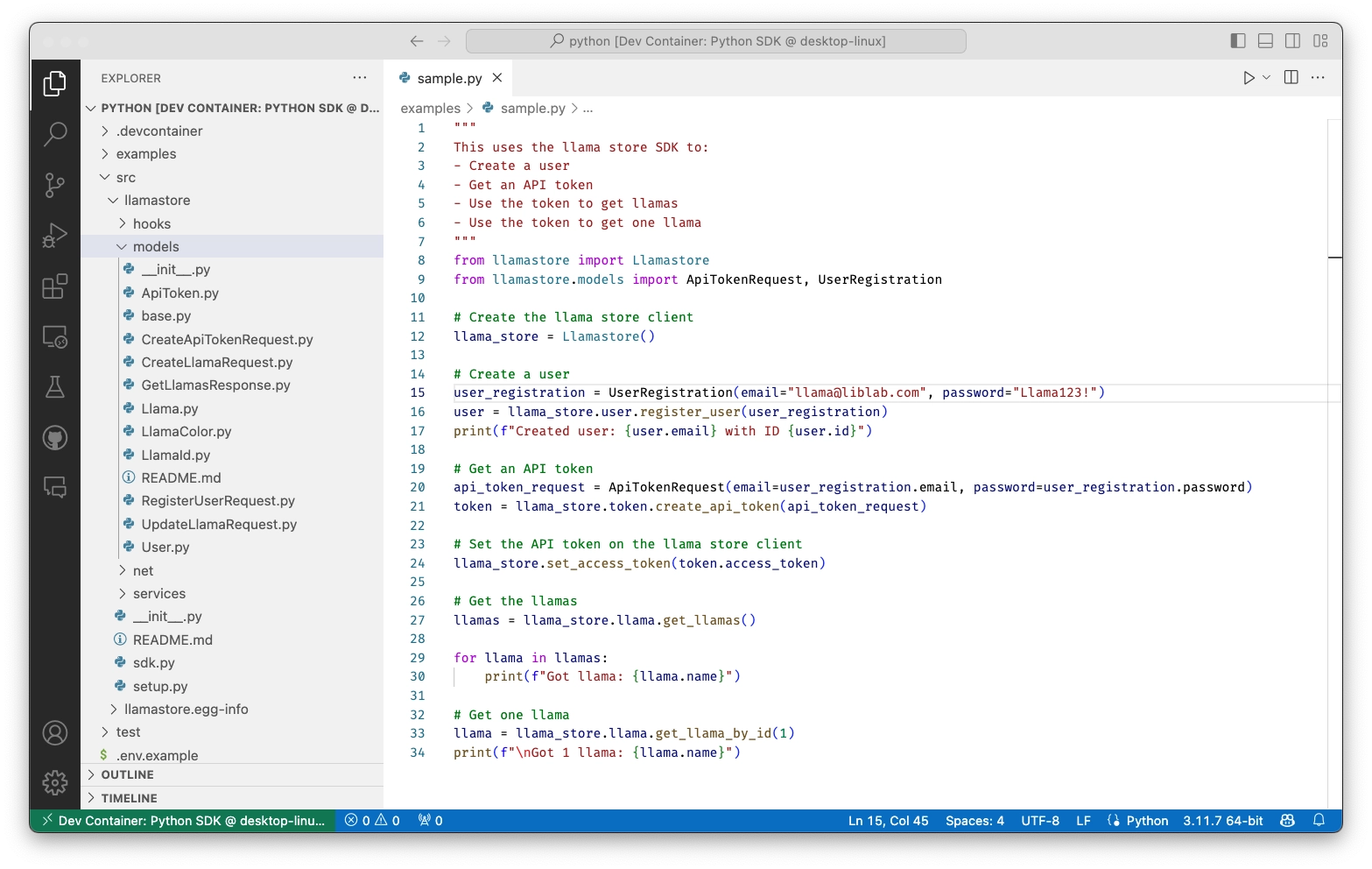
As an experienced engineer, I've learned the value of simplicity and ease of getting things done. Life is too short to spend on writing boilerplate code, or dealing with the complexities of lowest common denominator tooling. I want to focus on the business problem I'm trying to solve, not the plumbing.
This is why I'm always a fan of a well-crafted SDK, a tool that makes it easy to use a service or API. In this post we look at the process of creating SDKs, from concept to creation, and show how you can automate the process using liblab.
What is an SDK?
Let's start with the basic question - what is an SDK? An SDK, short for Software Development Kit, is a set of tools written in one or more programming languages that make it easier to use a service or API. For this post, I will focus on SDKs for APIs, providing a wrapper around the direct REST calls that a user might make against an API.
An SDK is a great abstraction layer. It is written in the language the developer uses, and provides language idiomatic ways to call the API, managing all the hard stuff for you such as the HTTP calls, the mapping of JSON to objects, authentication, retries, and so on.
A good SDK drastically reduces the code you have to write.
The importance of an SDK
SDKs are important to improve the developer experience of using your service or API. They allow your users to focus on the business problem they are trying to solve, rather than the plumbing of calling your API. This is just as important for public facing APIs from SaaS companies, as it is for internal APIs used by your own developers from your corporate microservices.
Some benefits include:
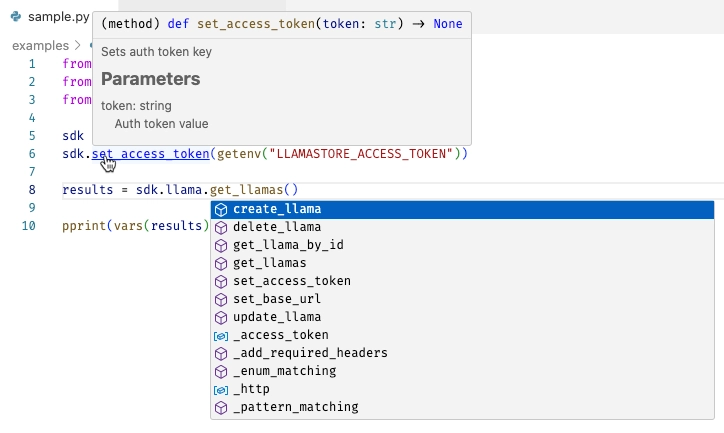
- Intellisense and code completion - you can see the methods and properties available to you, and the parameters they take in your IDE.
- Authentication - the SDK can handle the authentication process for you, so you don't have to worry about it.
- Built in best practices - you can embed best practices inside the SDK, such as retry logic, so that if a call fails due to rate limiting, the SDK will automatically retry the call after a short delay.
To learn more about the comparison between SDKs and calling APIs directly, check out our post SDK vs API, key distinctions.
How to Build an SDK
Creating SDKs is a multi-step process, and is very time consuming. Not only do you need to design and build the SDK, but you also will want to create SDKs in multiple languages to support your users needs.
This might be less important if you are building SDKs for internal APIs and you only use a single language - for example if you are a Java shop you may only need a Java SDK. However, if you are building a public facing API, you will want to support as many programming languages as possible, so that your users can use the language they are most comfortable with. You will probably want a TypeScript SDK or JavaScript SDK, a Python SDK, a C# SDK, a Java SDK, and so on depending on the programming language priorities of your users.
The steps you would take are:
- Design your SDK
- Build your SDK
- Document your SDK
- Test your SDK
- Publish your SDK
- Maintain your SDK
1. Design your SDK
The first step is to design the SDK. A typical pattern is to mimic the API surface, providing functions that act like your API endpoints. This is a great way to build an SDK - it means your documentation and other user guides can be essentially the same for your API and SDKs, with just different sample code to use the SDK rather than make an API call.
API specification
To do this you will need to know how your API works, which is why it is important that your API has documentation, ideally an API specification such as an OpenAPI spec. Some API designers will start from an OpenAPI spec, others will start with code and autogenerate the OpenAPI spec from that code. Either way, you need to have a good understanding of your API before you can start to design your SDK.
The act of designing your SDK can also be a great way to validate that you have a good, clean API design. If you find that your SDK is hard to design, or that you have to do a lot of work to make it easy to use, then this is a good sign that your API needs improvement. For some tips, check out our post on why your OpenAPI spec sucks.
Paths and components
OpenAPI specs have 2 sections that make designing your SDK easier - paths and components. The paths section defines the endpoints of your API, and the components section defines reusable components, such as schemas for request and response bodies, or security schemes.
You want to use components as much as possible to make it easier to understand the data that is being passed around. Using components also helps you to them as much as possible between endpoints.
For example, if you have an endpoint that returns a single user, it is cleaner to have that user defined as a components/schema/user object. You can then reference that in the endpoint that gets a single user, and wrap it as an array for an endpoint that gets multiple users.
From API spec to an SDK design
Once you have your API spec, you can start to design your SDK. A good design is to provide objects that wrap the requests and responses for your API endpoints, and methods that call the API endpoints.
You will need to consider:
- What objects will encapsulate the
components
- How
paths will be grouped and wrapped as methods
- The interface to handle authentication
- Each SDK language will have different idioms, libraries and best practices. You will need to decide how to handle these differences. This might be a challenge if you are not familiar with the language.
- How to handle best practices such as retries. Do you implement this yourself, or use a library?
- Naming conventions. It is important to create SDKs that use idiomatic code for the SDK language - for example, if you are building a Python SDK, you want to use Python idioms such as using
snake_case for method names, and PascalCase for class names, whereas TypeScript would use camelCase for method names.
2. Build your SDK
After you have designed your SDK, you can start to build the code implementation. This is a manual process, and is very time consuming, especially if you have SDKs in multiple languages.
Components
First you want to create objects to wrap the requests and responses for your API endpoints, defined in the components/schemas section of your OpenAPI spec. These objects are often referred to as models or DTOs (data transformation objects). These are usually 'simple' objects that have properties that map to the properties on the schema, and allow you to write JSON mapping code (or use a built in library) to automatically map the JSON to the object.
Sometimes the objects can be more complex. For example if your API specification defines an anyOf or oneOf - an endpoint that can return one of a range of possible types. Some languages can support this through a union type, others cannot, so you will need to decide how to handle these types. Remember, you need to do this for every SDK language you want to support.
SDK methods
Once you have your models, you can start to build the SDK methods that call your API endpoints. These functions can take models as parameters, and return the models as responses.
You will need to handle making HTTP requests, and the mapping of JSON to objects. You will also need to handle the authentication process, and any other best practices you want to build in such as persisting the HTTP connection, retries and logging.
These methods might also need parameters to match the parameters for the endpoint - both path parameters and query parameters.
For example, if the endpoint is GET /llama/{id} with the Id as a path parameter, you might have a method like this:
class Llama(BaseService):
def get_llama(self, id: int) -> Llama:
where the llama Id becomes a method parameter.
Grouping methods
A good practice is to group these functions into service classes. You might want to do it based off the endpoint - for example having the GET, POST, and PUT methods for a single endpoint in a single class.
API specifications can also define groupings of endpoints, such as OpenAPI tags, so you might want to group your functions based on these tags. You know your API, so pick a technique that works for you.
As you build these methods, you should abstract out as much logic as possible into base service classes, or helper methods. For example, you might want to abstract out the HTTP request logic, the JSON mapping logic, the authentication logic, and the retry logic. This way you can define it once, and share the logic with all your service methods.
SDK client
Finally you will want to put some kind of wrapper object, usually referred to as an SDK client, around the endpoints. This will be the single place to surface authentication, setting different URLs if you have a multi-tenant API, or support different API regions or environments. This is your users entry point to the SDK.
class Llamastore:
def __init__(self, access_token="", environment=Environment.DEFAULT) -> None:
self.llama_service = LlamaService(access_token)
def set_base_url(self, url: str) -> None:
def set_access_token(self, token: str) -> None:
3. Document your SDK
An SDK is only as good as its SDK documentation. As you create SDKs, you will also need to write documentation that shows how to install, configure, and use the SDK. You will need to keep the documentation in sync with the SDK, and update it as the SDK evolves. This will then need to be published to a documentation web page, or included in the SDK package.
OpenAPI specs support inline documentation, from descriptions of paths and components, to examples of parameters and responses. This is a great way to document your API, and you can use this to generate proper documentation for your users.
4. Test your SDK
Once your SDK is built, you need to ensure that it works as expected. This means writing unit tests that verify:
- The JSON expected by and returned by your API can map to the objects you have created
- The HTTP requests are being made correctly by the SDK methods to the right endpoints
- Authentication is implemented correctly
- The best practices such as retries work as expected
You should write unit tests that mock the real endpoint, as well as integration tests that call a real endpoint in a sandbox or other test environment.
5. Publish your SDK
Your finished SDK needs to be in the hands of your users. This means publishing it to a package manager, such as npm for JavaScript, or PyPi for Python.
For every SDK language you will need to create the relevant package manifest, with links to your SDK documentation, and publish it to the package manager. For internal SDKs, you might want to publish it to a private package manager, such as GitHub packages, or a private npm registry.
6. Maintain your SDK
It's not enough to just create SDKs once. As your API evolves, you need to update your both your SDK and SDK documentation to reflect the changes. This is a manual process, and is very time consuming, especially if you have SDKs in multiple languages.
Your users will expect your SDK to be in sync with your API, ideally releasing new features to your SDK as soon as they are released to the API. As well as the engineering effort to update the SDK and SDK documentation, you also need to ensure that during SDK development, your internal processes track API updates, create tickets for the work to update the SDK, and ensure that the SDK is released at the same time as the API.
Every new endpoint would mean a new SDK method, or a new class depending on how you have structured your SDK. Every new schema is a new model class. Every change to an existing endpoint or schema is a change to the existing SDK method or model class. You may also need to update any best practices, such as supporting new authentication schemes, or adding new retry logic.
You will also need to track breaking changes, and update your SDK version as appropriate - a major version bump for breaking changes, a minor version bump for new features, and a patch version bump for bug fixes.
Best practices for building the perfect SDK
When building an SDK, there are a number of best practices you should follow to ensure that your SDK is easy to use, and works well for your users.
- Provide good documentation and examples - your API spec should be full of well written descriptions, examples, and other documentation that can be ported to your SDK. This will make it easier for your users to get started quickly.
- Use idiomatic code - your SDK should use the idioms of the language you are building the SDK for. It should match the language's naming conventions, use standard libraries, and follow the language's best practices. For example, using
requests in Python, making all your C# methods async, using TypeScript's Promise for asynchronous methods, and so on.
- Embed security best practices - take advantage of security best practices, from using the latest version of any dependencies with mechanisms to monitor for patches and provide updates, to using the latest security protocols and libraries.
- Handle authentication - your SDK should handle authentication for your users. This might be as simple as providing a method to set an API key, or as complex as handling OAuth2. You should also provide a way to handle different environments, such as development, staging, and production.
Automating the SDK build with liblab
Creating SDKs is a lot of work that only gets bigger as your API grows, or you want to support more languages. This is where automation is your friend. liblab is a tool that can take your API specification, such as an OpenAPI spec, and autogenerate SDKs for you in multiple languages.
The SDK generation process will generate the models and service classes for you, with all the required mapping code. It will also generate your best practices such as authentication and retries, and you can configure these via a configuration file. You can also write code that is injected into the API lifecycle to add additional functionality, such as logging or custom authentication with the liblab hooks feature.


SDK generation is fast! A typical developer flow is to spend a few hours generating SDKs the first time as you configure the generation process to meet your needs. This is an iterative cycle of generate, check, adjust the configuration, then regenerate. Once you have your configuration the way you need, your SDKs are generated in seconds.
Adding more SDK languages is also fast - you add the new language to the configuration file, and regenerate.
liblab can also help you to keep your SDKs in sync with your API. As your API is updated, your SDK can be re-generated to match. For example, if your API spec lives in a git repository, you can set up a GitHub action to detect any changes, and regenerate your SDK, publishing the new SDK source code to your SDK repositories.
Finally liblab can generate your SDK documentation for you, with full code examples and all the documentation you need to get started. This is taken from your API specification, so is always in sync with your API.
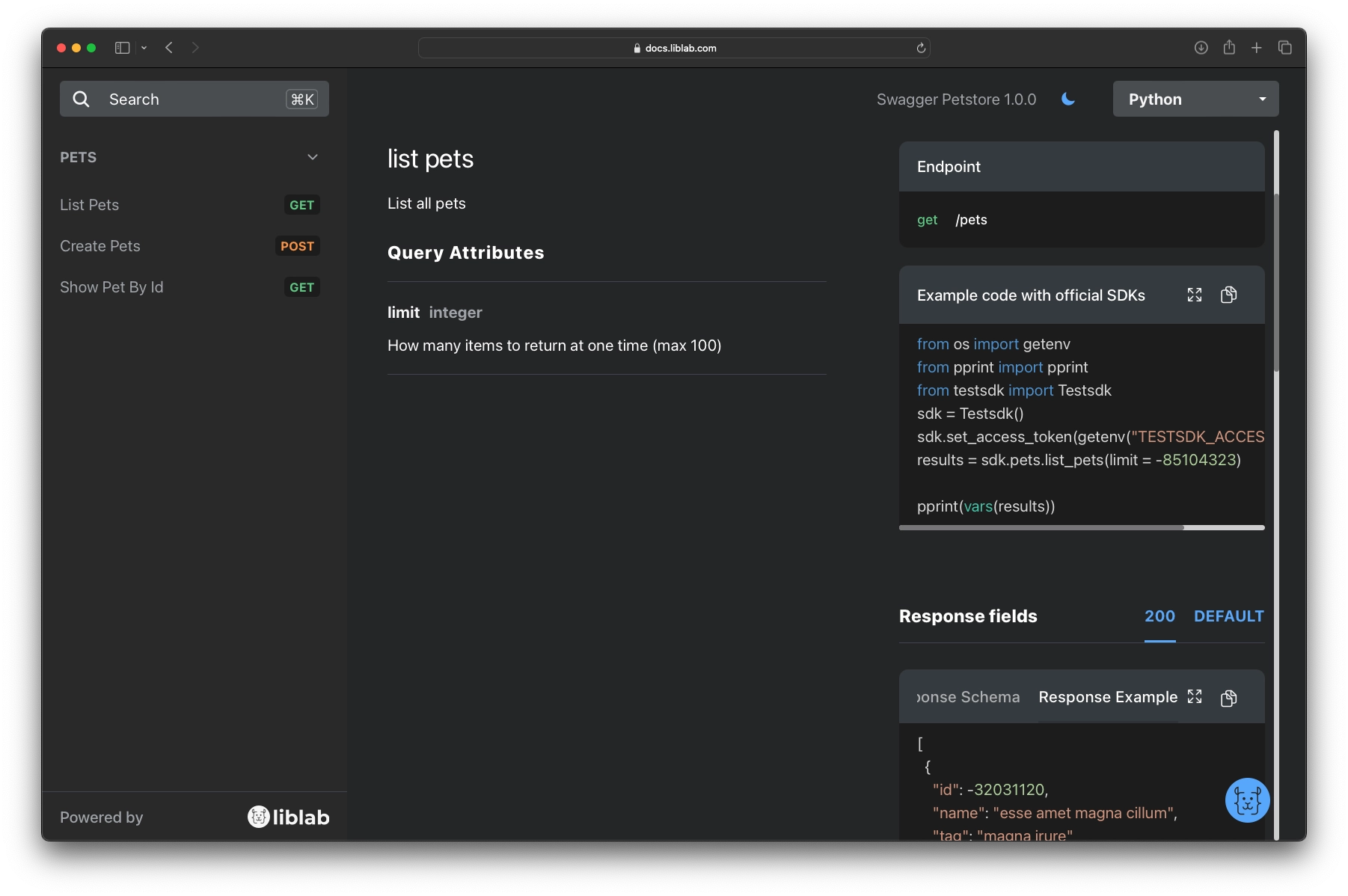

Conclusion
SDKs are a powerful way to improve the developer experience of your API. They come with a cost - the amount of work needed to generate them. This is why automation is so important. With liblab you can automate the process of generating SDKs, and keep them in sync with your API as it evolves.
Sign up for liblab today and start generating SDKs for your APIs in minutes.